Think IT から引用:
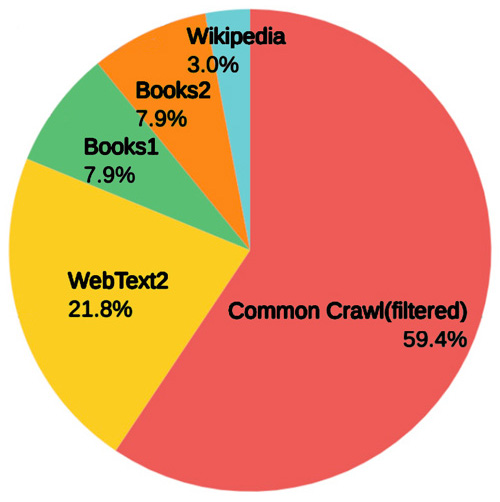
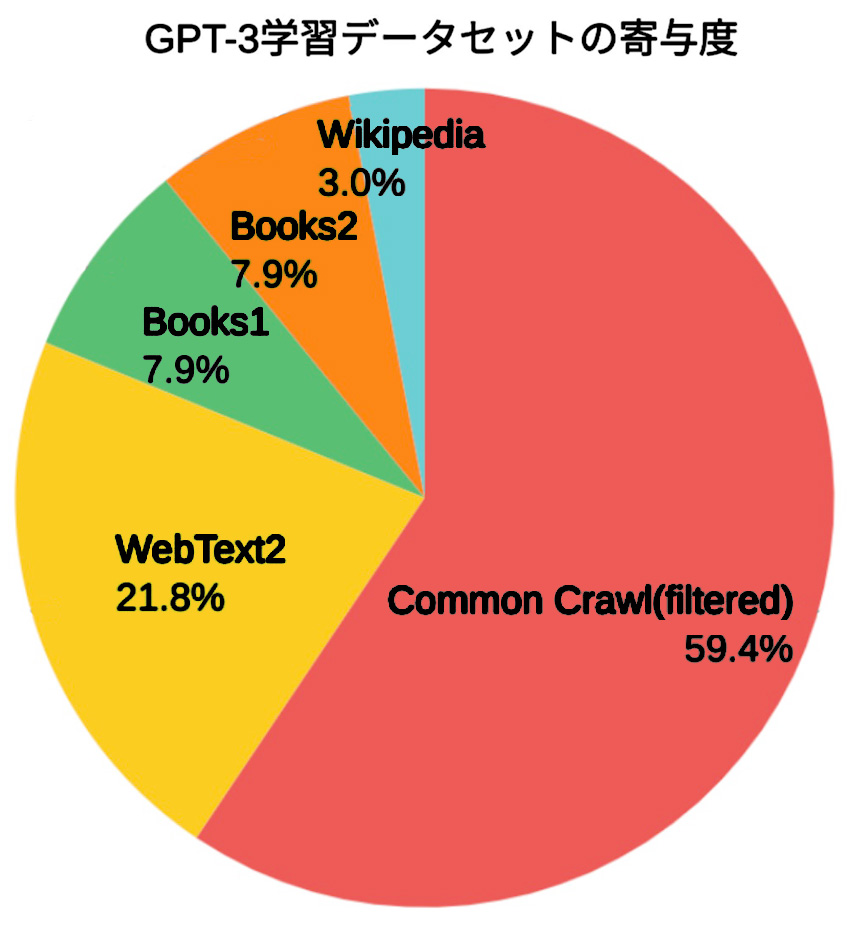
WebText2 は,Common Crawlコーパス以外のWebページのデータ。
Book1 と Book2 は書籍データ (どのような情報が使われたかについては明確にされていない。
|
- Common Crawl コーパス
- 世界最大のオープンなコーパス
- インターネットのWebサイトをクロール (巡航)し,そこに掲載されているテキストデータをスクレイピング (データ取得)して,コーパスに。
- https://commoncrawl.org/
- コーパス corpus
- 文章や会話などを大量に集めて,コンピュータで処理しやすいように構造化した,言語データベース。
|